
Memory Management in C++: allocation
Memory Management in C++
- Introduction and design
- First steps
- Allocation
- Deallocation
Welcome back, dear reader!
In the previous post in the series we walked through dumping our big memory chunk to understand its contents. This time we’ll start using this memory to allocate smaller chunks by user request.
Let’s get to it!
What’s a chunk, again?
The idea behind our memory manager was to divide a given big memory chunk into smaller chunks of user-requested size. We decided these smaller memory chunks would look like this:
struct cMemoryChunk
{
bool m_isInUse;
unsigned int m_bytes;
cMemoryChunk *m_previous;
cMemoryChunk *m_next;
};So, where do we store the memory a user requested? I don’t see any field for it. Glad you asked.
We’re going to treat this cMemoryChunk struct as the header of the user-requested slice of the total memory we’re managing. The real memory the user requested will be right next to it. Does that sound right?
Let’s check it with an example.
Anatomy of a chunk
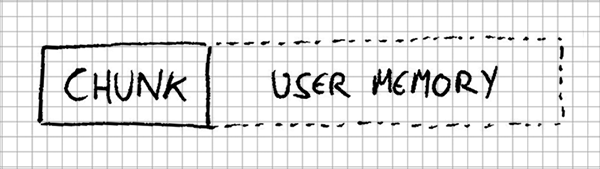
Suppose the start of the memory we manage is at 0x00000000 and the user requests 4 bytes from it. We would need to store the cMemoryChunk header first, and then the 4 bytes we were requested, right?
Assume we already had a method on our manager called allocate that receives the number of bytes an user has requested. Let’s say we called:
cMemoryManager memoryManager(32);
memoryManager.allocate(4);
std::cout << memoryManager.dump() << std::endl;With the previous definition we gave for our chunks, we’d expect the dump to be:
00000000: 01:CD:CD:CD:04:00:00:00:00:00:00:00:00:00:00:00 ................
00000010: AA:AA:AA:AA:CD:CD:CD:CD:CD:CD:CD:CD:CD:CD:CD:CD ................This dump means:
01:CD:CD:CD -> 0x01, it is in use. The 0xCD ones are padding.
04:00:00:00 -> This chunk uses 4 bytes.
00:00:00:00 -> Address of the previous chunk (no previous chunk).
00:00:00:00 -> Address of the next chunk (no next chunk).
AA:AA:AA:AA -> The 4 bytes the user has requested, initialized as 0xAA for convenience.
CD:CD:CD:CD -> Unused memory
CD:CD:CD:CD -> Unused memory
CD:CD:CD:CD -> Unused memoryWith this in mind, let’s answer some questions so we understand the key points here.
What’s the address of the chunk?
We’re, again, saying the chunk is just the header of the user-requested memory. And we’ve assumed the memory we manage starts at 0x00000000.
So that’s it, the chunk starts at 0x00000000. Or, chunk == 0x00000000.
What’s the address of the user-requested memory?
We’d want to keep this header somewhat private to the manager and we don’t want to return its address to the user. Instead, we want to return the start of the AA:AA:AA:AA we saw in the dump. What’s that address?
In the dump you can see it starts at 0x00000010. More generally, the address is chunk + sizeof(cMemoryChunk).
Now that we’ve got this straight, let’s implement the allocate method!
Allocate
If we remember malloc, it has the following signature:
void *malloc(size_t size);Did you notice the void * return value? That’s the address to the start of the memory the system is returning to the user. With this in mind we’re defining allocate as:
void *allocate(unsigned int bytes);It’s not exactly the same signature because we’re using unsigned int instead of size_t (it is a more explicit type, but type size_t can be bigger than, equal to or smaller than unsigned int depending on the platform, so be careful).
First steps on allocation
To obtain the previous dump, we used the following code:
void *cMemoryManager::allocate(unsigned int bytes)
{
unsigned char *chunkAddress = m_memory;
cMemoryChunk *chunk = reinterpret_cast<cMemoryChunk *>(m_memory);
const unsigned int chunkSize = sizeof(cMemoryChunk);
// update the previously free chunk
chunk->m_isInUse = true;
chunk->m_bytes = bytes;
// update manager-level data
m_freeBytesCount -= chunk->m_bytes + chunkSize;
// trashing on allocation?
if (static_cast<int>(m_trashing) & static_cast<int>(eTrashing::ON_ALLOCATION))
{
memset(chunkAddress + chunkSize, static_cast<int>(eTrashingValue::ON_ALLOCATION), chunk->m_bytes);
}
// the memory we give back to the user doesn't include the chunk itself
return chunkAddress + chunkSize;
}I’m sure you have noticed something wrong already, but let’s understand it step by step and address the problems later.
First of all, we get a pointer to the start of the memory we’re managing into chunkAddress. We get another pointer to it into chunk but this time we interpret it as a cMemoryChunk. This way we can reference its members and treat that slice of the memory as a fully-fledged cMemoryChunk instance.
What’s the total size of the user-requested memory, then? For each memory request we need to create a header, so we’ll be using sizeof(cMemoryChunk) + bytes. That’s what we subtract from m_freeBytesCount, so we can keep track of the remaining free memory.
Do you remember the AA:AA:AA:AA bytes we had in the previous dump? Checking back the previous entry in the series we defined these trashing options:
#define MemoryManagerTrashingOptions \
TO(NONE, 0, 0xFF) \
TO(ON_INITIALIZATION, 1 << 0, 0xCD) \
TO(ON_ALLOCATION, 1 << 1, 0xAA) \
TO(ON_DEALLOCATION, 1 << 2, 0xDD) \
TO(ON_ALL, ON_INITIALIZATION | ON_ALLOCATION | ON_DEALLOCATION, 0xFF) \This way, we know the memory we’re returning to the user is initialized to something we can easily see in the dump.
Finally, the address we return to the user is the one right after the header, or chunk + sizeof(cMemoryChunk).
I already heard your brain yelling: okay, okay, but this code only allows to have one chunk at a time!. You are right, that’s the problem I mentioned earlier! Let’s fix that now!
Creating new chunks
For our memory manager, there’s a thing that must hold true at any given time: we need an empty chunk at the tail of the list of chunks. If you remember, the first thing we do when we build the manager is creating an empty chunk.
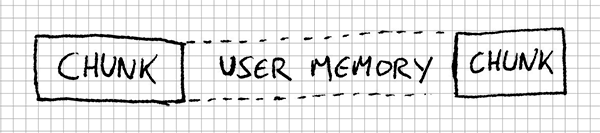
So, as part of the allocate method we need to create this trailing empty chunk. How do we do it?
void *cMemoryManager::allocate(unsigned int bytes)
{
...
// build a new chunk from the remaining space in the chunk
unsigned char *newChunkAddress = chunkAddress + chunkSize + bytes;
cMemoryChunk *newChunk = new (newChunkAddress) cMemoryChunk(chunk->m_bytes - bytes - chunkSize);
newChunk->m_previous = chunk;
newChunk->m_next = chunk->m_next;
// link it appropriately with the next chunk, if any
if (newChunk->m_next != nullptr)
{
newChunk->m_next->m_previous = newChunk;
}
...
}Step by step, again.
Where does the new chunk start? Well, we know a chunk occupies the size of the header and the user-requested memory, right? That’s where we point newChunkAddress to.
We’ve got the address, but we want to interpret that memory as a cMemoryChunk. This time, we’re building a new cMemoryChunk in that memory address, so we’re using the placement new instead of reinterpreting the address. But, we see in the code: cMemoryChunk(chunk->m_bytes - bytes - chunkSize), why is that?
When we build a cMemoryChunk we tell it how many bytes are free from it and on. Because we always start with an empty chunk, we assume we’ll have the correct number of free bytes until the next chunk or the end of our managed memory.
Again, a chunk occupies the size of the header and the user-requested memory; so the new available memory after the chunk is the one it had, minus the bytes the user requested, minus the memory it takes to allocate a new header for the empty trailing chunk.
Finally, we’ve got to link the new chunk with the previous and next ones. We’ll always have a previous one, as we’ve earlier said this chunk was the tail. However, later on when we deallocate chunks, we can have an empty chunk in between two in-use chunks. When we use that empty space to create a new chunk, we’ll have a following one that’s in use (so the new one isn’t the tail anymore). In other words, it’s a doubly-linked list and we have to keep the links pointing to the right places.
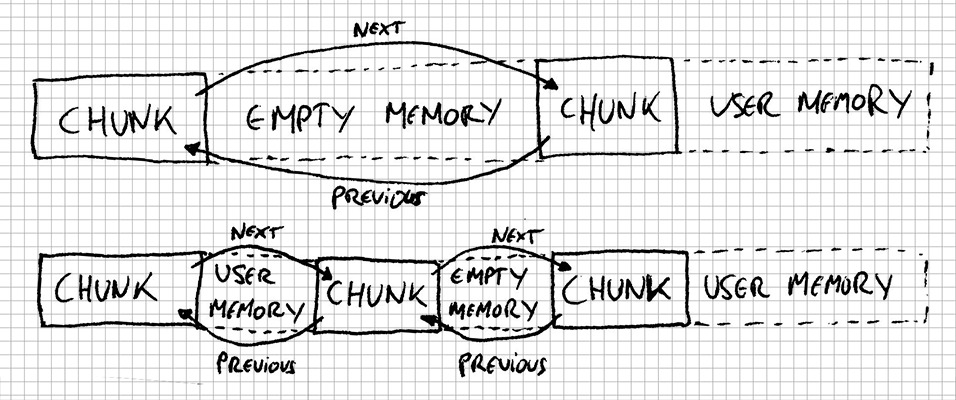
Phew! So, what’s missing? So far we’ve created a new chunk, but if we were to call allocate several times in a row we would be overriding the same first chunk over and over. What are we missing?
void *cMemoryManager::allocate(unsigned int bytes)
{
...
// find the first free chunk that can store the requested number of bytes
cMemoryChunk *chunk = reinterpret_cast<cMemoryChunk *>(m_memory);
while (chunk != nullptr)
{
// need enough bytes to allocate the requested bytes and a new chunk
if (!chunk->m_isInUse && chunk->m_bytes >= (bytes + chunkSize))
{
break;
}
chunk = chunk->m_next;
}
// might not be able to allocate it
if (chunk == nullptr)
{
return nullptr;
}
...
}Instead of starting at m_memory, which is the pointer to the start of the memory we manage, we have to find the first chunk that can store the memory that’s been requested. It can happen that we’ve ran out of usable memory, so we’ll be returning nullptr when we can’t hand in any memory to the user.
If you double-check, the test chunk->m_bytes >= (bytes + chunkSize) is using the same total size we mentioned earlier when creating a new chunk.
Allocate method put together
Now that we’ve seen the parts, let’s see the full code of the allocate method:
void *cMemoryManager::allocate(unsigned int bytes)
{
const unsigned int chunkSize = sizeof(cMemoryChunk);
// find the first free chunk that can store the requested number of bytes
cMemoryChunk *chunk = reinterpret_cast<cMemoryChunk *>(m_memory);
while (chunk != nullptr)
{
// need enough bytes to allocate the requested bytes and a new chunk
if (!chunk->m_isInUse && chunk->m_bytes >= (bytes + chunkSize))
{
break;
}
chunk = chunk->m_next;
}
// might not be able to allocate it
if (chunk == nullptr)
{
return nullptr;
}
unsigned char *chunkAddress = reinterpret_cast<unsigned char *>(chunk);
// build a new chunk from the remaining space in the chunk
unsigned char *newChunkAddress = chunkAddress + chunkSize + bytes;
cMemoryChunk *newChunk = new (newChunkAddress) cMemoryChunk(chunk->m_bytes - bytes - chunkSize);
newChunk->m_previous = chunk;
newChunk->m_next = chunk->m_next;
// link it appropriately with the next chunk, if any
if (newChunk->m_next != nullptr)
{
newChunk->m_next->m_previous = newChunk;
}
// update the previously free chunk
chunk->m_next = newChunk;
chunk->m_bytes = bytes;
chunk->m_isInUse = true;
// update manager-level data
m_freeBytesCount -= chunk->m_bytes + chunkSize;
// trashing on allocation?
if (static_cast<int>(m_trashing) & static_cast<int>(eTrashing::ON_ALLOCATION))
{
memset(chunkAddress + chunkSize, static_cast<int>(eTrashingValue::ON_ALLOCATION), chunk->m_bytes);
}
// the memory we give back to the user doesn't include the chunk itself
return chunkAddress + chunkSize;
}We can improve it further and add a new case on the search for a valid chunk. Stay with me as I explain it.
We could also use a free chunk that’s followed by another one even when the user-requested bytes fit in it but a new header doesn’t: we’d skip creating a new header in it, link the chunk to the next one and say it uses as many extra bytes as needed to fill up to the next chunk. Got it? :)
Testing it!
Alright! Let’s see if our hard work yielded something useful! This is our test program:
cMemoryManager memoryManager(80);
void *firstAllocation = memoryManager.allocate(sizeof(unsigned int));
void *secondAllocation = memoryManager.allocate(sizeof(int) * 4);
std::cout << memoryManager.dump() << std::endl;
unsigned int *firstAsUInt = static_cast<unsigned int *>(firstAllocation);
int *secondAsInt = static_cast<int *>(secondAllocation);
*firstAsUInt = 100000000;
secondAsInt[0] = 10;
secondAsInt[2] = -10;
std::cout << memoryManager.dump() << std::endl;We’d have these dumps:
0106CFF8: 01:CD:CD:CD:04:00:00:00:00:00:00:00:0C:D0:06:01 ................
0106D008: AA:AA:AA:AA:01:CD:CD:CD:10:00:00:00:F8:CF:06:01 ................
0106D018: 2C:D0:06:01:AA:AA:AA:AA:AA:AA:AA:AA:AA:AA:AA:AA ,...............
0106D028: AA:AA:AA:AA:00:CD:CD:CD:0C:00:00:00:0C:D0:06:01 ................
0106D038: 00:00:00:00:CD:CD:CD:CD:CD:CD:CD:CD:CD:CD:CD:CD ................
0106CFF8: 01:CD:CD:CD:04:00:00:00:00:00:00:00:0C:D0:06:01 ................
0106D008: 00:E1:F5:05:01:CD:CD:CD:10:00:00:00:F8:CF:06:01 ................
0106D018: 2C:D0:06:01:0A:00:00:00:AA:AA:AA:AA:F6:FF:FF:FF ,...............
0106D028: AA:AA:AA:AA:00:CD:CD:CD:0C:00:00:00:0C:D0:06:01 ................
0106D038: 00:00:00:00:CD:CD:CD:CD:CD:CD:CD:CD:CD:CD:CD:CD ................First dump: several allocations
Okay, so we’ve performed two allocations: one for a single unsigned int value and one for 4 int values. In terms of chunks, this would’ve been the step by step evolution:
- We create the memory manager and a single empty chunk with it.
- We perform the first allocation, using the empty chunk and creating an empty one at its tail.
- We perform the second allocation, using the former tail and creating a new empty trailing one.
Is that what we’ve got?
First chunk (0x0106CFF8):
01:CD:CD:CD -> It is in use.
04:00:00:00 -> Using 4 bytes.
00:00:00:00 -> No previous chunk.
0C:D0:06:01 -> Next chunk is at 0x0106D00C
AA:AA:AA:AA -> Allocated bytes, still untouched.
Second chunk (0x0106D00C):
01:CD:CD:CD -> It is in use.
10:00:00:00 -> Using 16 bytes.
F8:CF:06:01 -> Previous chunk is at 0x0106CFF8.
2C:D0:06:01 -> Next chunk is at 0x0106D02C.
AA:AA:AA:AA -> Allocated bytes, still untouched.
AA:AA:AA:AA -> Allocated bytes, still untouched.
AA:AA:AA:AA -> Allocated bytes, still untouched.
AA:AA:AA:AA -> Allocated bytes, still untouched.
Third chunk (0x0106D02C):
00:CD:CD:CD -> It is not in use.
0C:00:00:00 -> It has 12 empty bytes after it.
0C:D0:06:01 -> Previous chunk is at 0x0106D00C.
00:00:00:00 -> No next chunk.
CD:CD:CD:CD -> Unused memory.
CD:CD:CD:CD -> Unused memory.
CD:CD:CD:CD -> Unused memory.Great! Looks like it’s working! Good job :)
Second dump: user-modified memory
What would happen to the memory when the user modifies the memory we returned? Let’s just focus on the 0xAA bits, which are the ones modified:
First chunk's user-requested memory:
00:E1:F5:05 -> 0x05F5E100 == 100000000 *firstAsUInt = 100000000;
Second chunk's user-requested memory:
0A:00:00:00 -> 0x0000000A == 10 secondAsInt[0] = 10;
AA:AA:AA:AA -> Unchanged
F6:FF:FF:FF -> 0xFFFFFFF6 == -10 (check bonus) secondAsInt[2] = -10;
AA:AA:AA:AA -> UnchangedPhew, it worked flawlessly! Great job!
Bonus: two’s complement
Note that 0xFFFFFFF6 is a negative number in two’s complement. To get the decimal value we’ve got to invert all bits and then add 1 in its binary representation, or subtract the value to its most negative number: 0x100000000 (yes, that’s 9 digits because we’re using a 4-byte number). With that, we’ve got:
0x100000000 <- 9 digits
- 0x0FFFFFFF6 <- 9 digits (pre-filled with a 0)
==================
0x00000000A <- 9 digitsThe result is -0x0A, which is -10 in decimal as we expected.
This is the end of this entry! You can find the code we’ve created here.
In the next entry we’ll explore the deallocation of chunks and which problems arise when doing so.
Thanks a lot for reading!
Memory Management in C++
- Introduction and design
- First steps
- Allocation
- Deallocation